Our Data Visualizations
Explore our interactive visualizations showcasing key insights and trends derived from our comprehensive data analysis.
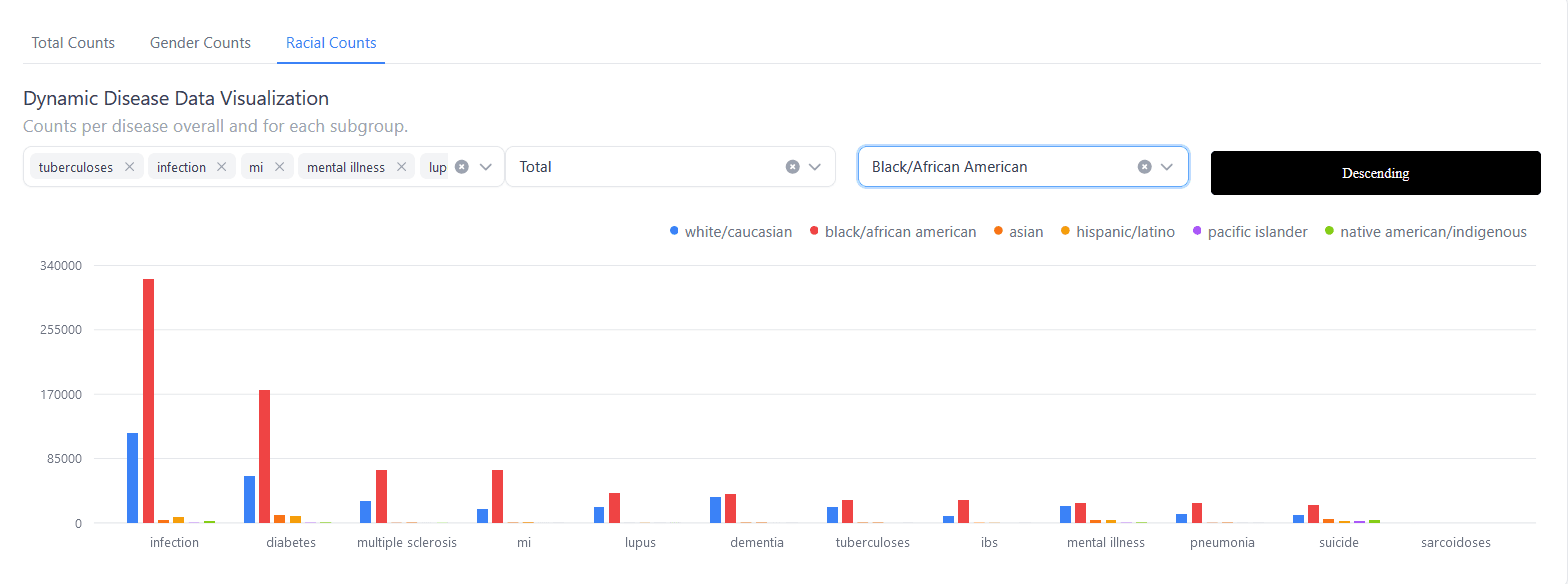
Trends Overview
Discover the evolving trends and patterns identified in our datasets, providing valuable insights into emerging topics and focus areas.
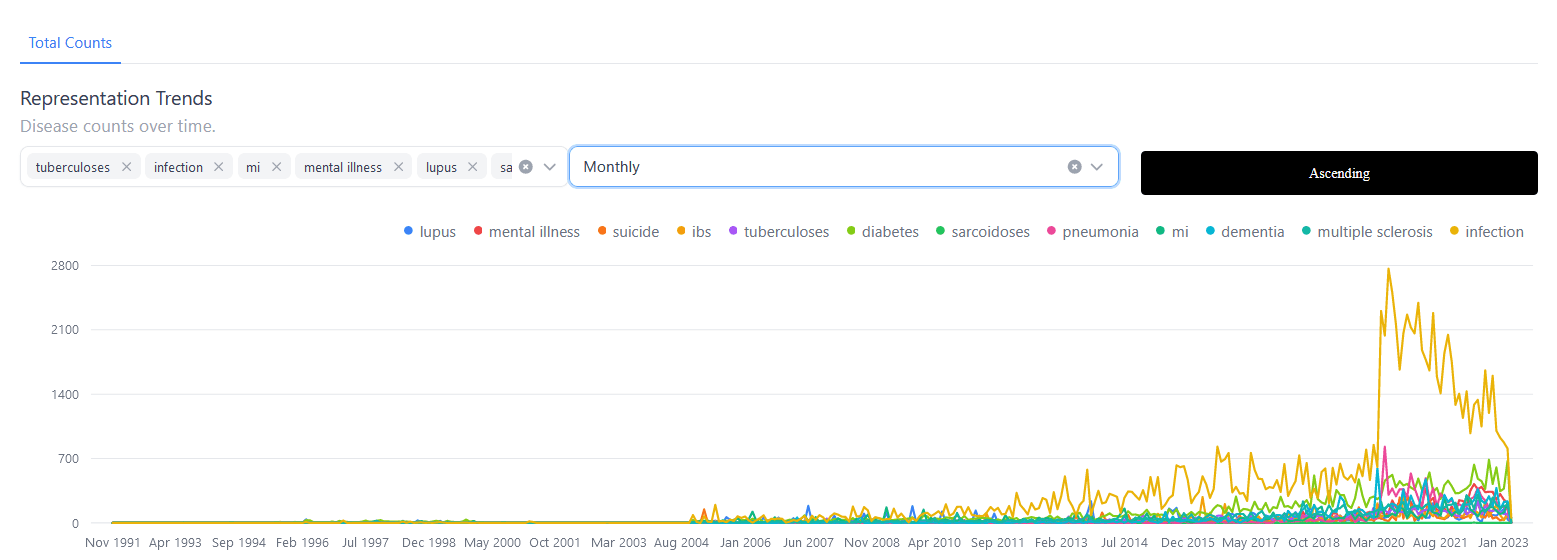
Race Distribution Analysis
A detailed breakdown of race distribution, highlighting the demographic diversity in our datasets and bringing attention to representation in health data.