Models in the Wild
Big Models vs Real World Data?
April 29, 2024
Written by BittermanLab
Models in the Wild
In this section, we delve into how various models perform in real-world scenarios, considering factors like size, alignment method, and language.
Variation Across Alignment Strategies
We examined how different alignment strategies affected the performance of the LLama2 70b series models concerning race and gender. Surprisingly, none of the alignment methods or in-domain continued pre-training improved the base models' accuracy in reflecting real-world prevalence. In fact, some alignment strategies seemed to influence the models' decisions in unexpected ways.
We observed similar trends across different models, such as Mistral and Qwen, where alignment methods didn't significantly alter the models' rankings of races or genders. However, models that underwent specific alignment methods or continued pre-training on medical domain data showed more noticeable variations in their rankings.
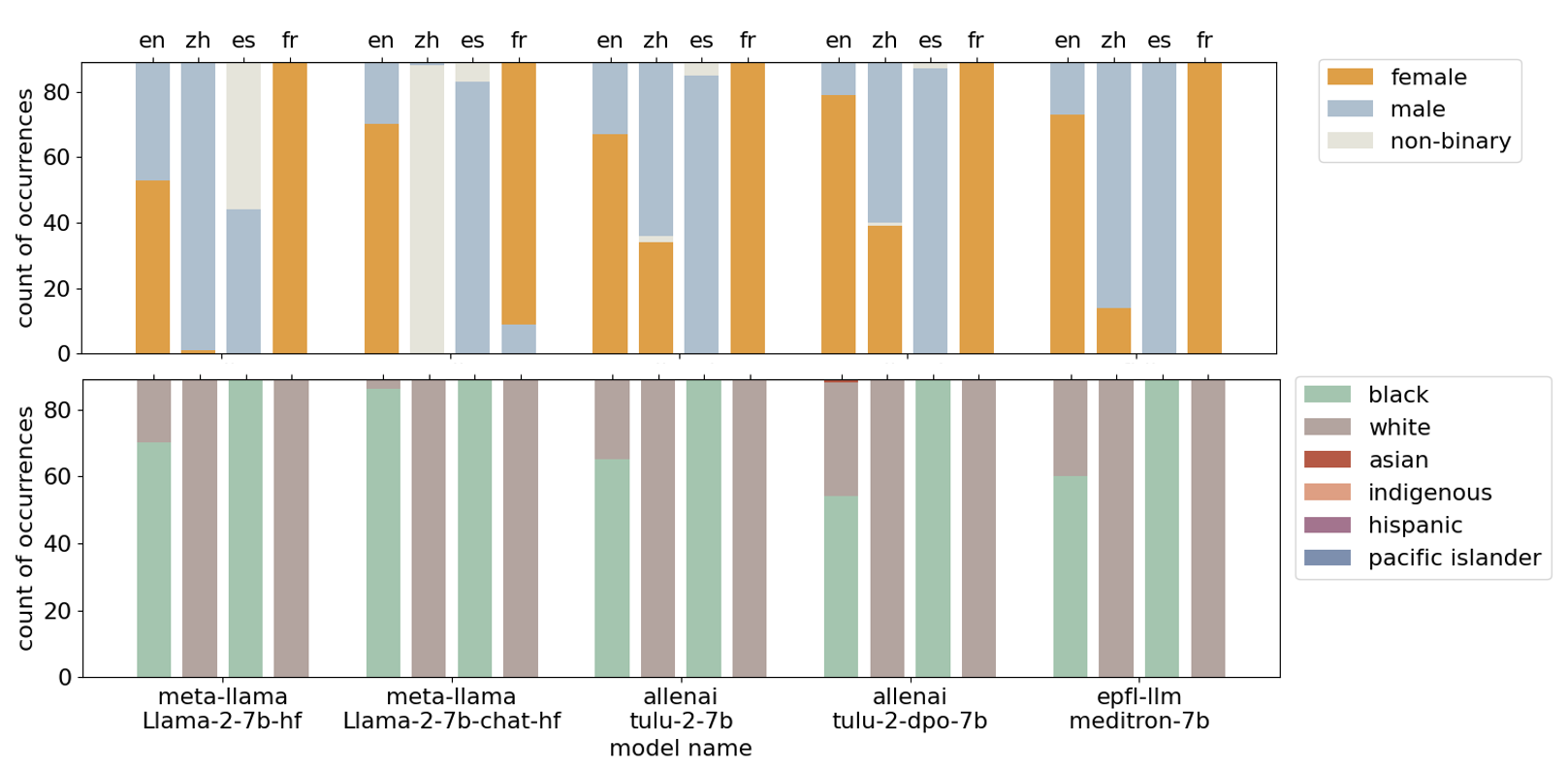
Models' Representation Across Different Languages
We also noticed differences in how models represented genders and races across different languages. For example, models generally showed a preference toward females in Chinese but males in French. Similarly, the racial preferences varied depending on the language, with templates in English and Spanish favoring Black race, while those in Chinese and French favored White race.
Interestingly, the Qwen1.5 models, which were predominantly trained on English and Chinese data, exhibited strong biases toward Asian race in Chinese and English templates, and Black race in Spanish and French templates.
Despite attempts to correct these biases through alignment methods or continued pre-training on in-domain text, the underlying biases persisted, highlighting the complexity of mitigating biases in language models.